

Speed-Aware Audio-Driven Speech Animation using Adaptive Windows
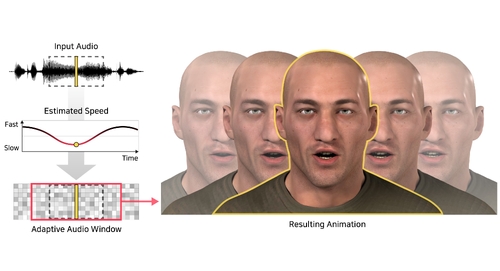
DescriptionWe present a novel method that can generate realistic speech animations of a 3D face from audio using multiple adaptive windows. In contrast to previous studies that use a fixed size audio window, our method accepts an adaptive audio window as input, reflecting the audio speaking rate to use consistent phonemic information. Our system consists of three parts. First, the speaking rate is estimated from the input audio using a neural network trained in a self-supervised manner. Second, the appropriate window size that encloses the audio features is predicted adaptively based on the estimated speaking rate. Another key element lies in the use of multiple audio windows of different sizes as input to the animation generator: a small window to concentrate on detailed information and a large window to consider broad phonemic information near the center frame. Finally, the speech animation is generated from the multiple adaptive audio windows. Our method can generate realistic speech animations from in-the-wild audios at any speaking rate, i.e., fast raps, slow songs, as well as normal speech. We demonstrate via extensive quantitative and qualitative evaluations including a user study that our method outperforms state-of-the-art approaches.
Technical Papers Fast Forward Presenter
Event Type
Technical Papers
TimeTuesday, 3 December 20249:00am - 12:00pm JST

LocationHall C, C Block, Level 4



