

Multimodal Learning for Autoencoders
SessionPosters Presentation
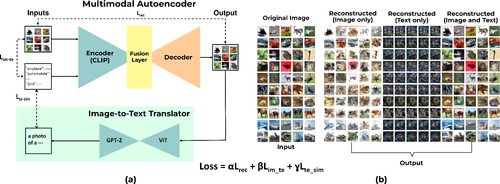
DescriptionWe propose Multimodal Autoencoder architecture and training scheme, in which images are reconstructed using both image and text inputs, rather than just images.


Event Type
Poster
TimeThursday, 5 December 20241:00pm - 2:00pm JST

LocationLobby Gallery (1) & (2), G Block, Level B1



TE
EH
