

TrailBlazer: Trajectory Control for Diffusion-Based Video Generation
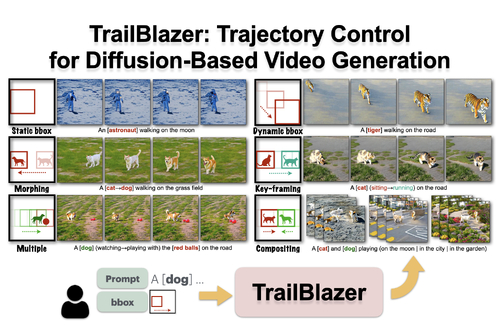
DescriptionLarge text-to-video (T2V) models such as Sora have the potential to revolutionize visual effects and the creation of some types of movies. Current T2V models require tedious trial-and-error experimentation to achieve desired results, however. This motivates the search for methods to directly control desired attributes. In this work, we take a step toward this goal, introducing a method for high-level, temporally-coherent control over the basic trajectories and appearance of objects. Our algorithm, TrailBlazer, allows the general positions and (optionally) appearance of objects to be controlled simply by keyframing approximate bounding boxes and (optionally) their corresponding prompts. Importantly, our method does not require a pre-existing control video signal that already contains an accurate outline of the desired motion, yet the synthesized motion is surprisingly natural with emergent effects including perspective and movement toward the virtual camera as the box size increases. The method is efficient, making use of a pre-trained T2V model and requiring no training or fine-tuning, with negligible additional computation. Specifically, the bounding box controls are used as soft masks to guide manipulation of the self-attention and cross-attention modules in the video diffusion model. While our visual results are limited by those of the underlying model, the algorithm may generalize to future models that use standard self- and cross-attention components.


Event Type
Technical Papers
TimeTuesday, 3 December 20249:00am - 12:00pm JST

LocationHall C, C Block, Level 4



