

BlobGEN-3D: Compositional 3D-Consistent Freeview Image Generation with 3D Blobs
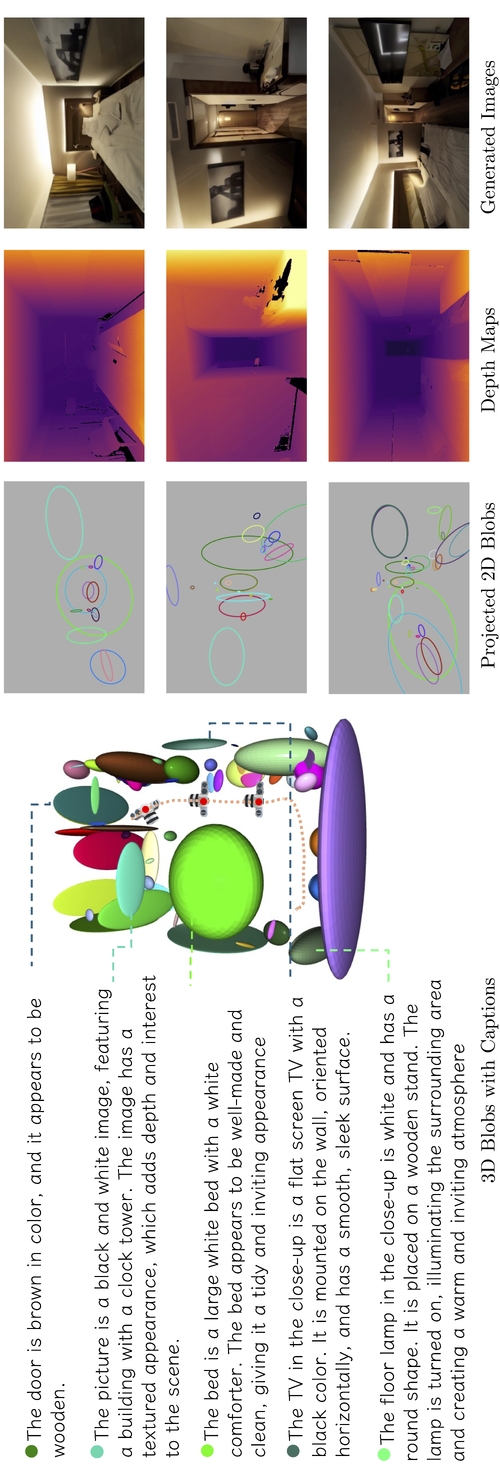
DescriptionRecent advances in text-to-image diffusion models have significantly enhanced image generation quality, when trained on internet-scale data. However, existing methods are constrained by their reliance on image or scene-level conditions, limiting their ability to synthesize composable 3D objects in a complex scene. To address these limitations, we propose BlobGEN-3D, a novel approach that decouples compositional 3D scene representation from 2D image generation, enabling direct controllability in the 3D space while fully leveraging the capabilities of 2D diffusion models. Specifically, BlobGEN-3D utilizes object-level 3D blobs with rich textual descriptions as the 3D scene representation, which is amenable to 2D projection, and is seamlessly integrable with 2D diffusion models. Based on this representation, we introduce an auto-regressive pipeline for freeview image generation, by conditioning the pretrained blob-grounded 2D text-to-image
diffusion model on the previously generated image. Our method has three key features: (i) it enables modular representation of 3D scene elements; (ii) coherent cross-view 2D generation; and (iii) manipulation of object appearance in the generated image sequences. Our method not only competes with the existing multi-view and optimization-based approaches, but also offers object-level appearance control, which was not possible before with alternatives that solely rely on scene-level descriptions, or image captions.
diffusion model on the previously generated image. Our method has three key features: (i) it enables modular representation of 3D scene elements; (ii) coherent cross-view 2D generation; and (iii) manipulation of object appearance in the generated image sequences. Our method not only competes with the existing multi-view and optimization-based approaches, but also offers object-level appearance control, which was not possible before with alternatives that solely rely on scene-level descriptions, or image captions.
Event Type
Technical Papers
TimeTuesday, 3 December 20249:00am - 12:00pm JST

LocationHall C, C Block, Level 4



