

PuzzleAvatar: Assembling 3D Avatars from Personal Albums
SessionHand and Human
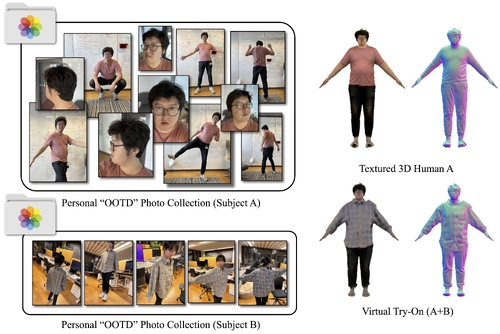
DescriptionGenerating personalized 3D avatars is crucial for AR/VR. However, recent text-to-3D methods that generate avatars for celebrities or fictional characters, struggle with everyday people. Methods for faithful reconstruction typically require full-body images in controlled settings. What if a user could just upload their personal "OOTD" (Outfit Of The Day) photo collection and get a faithful avatar in return? The challenge is that such casual photo collections contain diverse poses, challenging viewpoints, cropped views, and occlusion (albeit with a consistent outfit, accessories and hairstyle). We address this novel "Album2Human" task by developing PuzzleAvatar, a novel model that generates a faithful 3D avatar (in a canonical pose) from a personal OOTD album, while bypassing the challenging estimation of body and camera pose. To this end, we fine-tune a foundational vision-language model (VLM) on such photos, encoding the appearance, identity, garments, hairstyles, and accessories of a person into (separate) learned tokens and instilling these cues into the VLM. In effect, we exploit the learned tokens as "puzzle pieces" from which we assemble a faithful, personalized 3D avatar. Importantly, we can customize avatars by simply inter-changing tokens. As a benchmark for this new task, we collect a new dataset, called PuzzleIOI, with 41 subjects in a total of nearly 1K OOTD configurations, in challenging partial photos with paired ground-truth 3D bodies. Evaluation shows that PuzzleAvatar not only has high reconstruction accuracy, outperforming TeCH and MVDreamBooth, but also a unique scalability to album photos, and strong robustness. Our model and data will be public.


Event Type
Technical Papers
TimeFriday, 6 December 20243:31pm - 3:43pm JST

LocationHall B7 (1), B Block, Level 7


