

GPU Coroutines for Flexible Splitting and Scheduling of Rendering Tasks
SessionEnhancing, Saliency
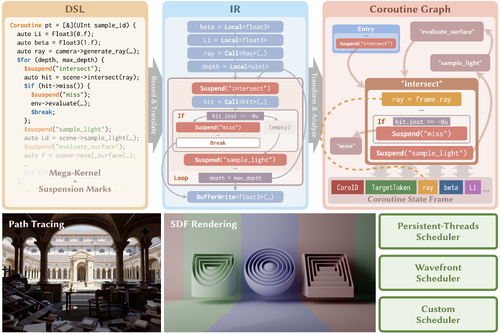
DescriptionWe introduce coroutines into GPU kernel programming, providing an automated solution for flexible splitting and scheduling of rendering tasks. This approach addresses a prevalent challenge in harnessing the power of modern GPUs for complex, imbalanced graphics workloads like path tracing. Usually, to accommodate the SIMT execution model and latency-hiding architecture, developers have to decompose a monolithic mega-kernel into smaller sub-tasks for improved thread coherence and reduced register pressure. However, involving the handling of intricate nested control flows and numerous interdependent program states, this process can be exceedingly tedious and error-prone when performed manually.
Coroutines, a building block for asynchronous programming in many high-level CPU languages, exhibit untapped potential for restructuring GPU kernels due to their versatility in control representation. By extending Luisa [Zheng et al. 2022], we implement an asymmetric, stackless coroutine model with programming language support and multiple built-in schedulers for modern GPUs. To showcase the effectiveness of our model and implementation, we examine them in different application scenarios, including path tracing, SDF rendering, and incorporation with custom passes.
Coroutines, a building block for asynchronous programming in many high-level CPU languages, exhibit untapped potential for restructuring GPU kernels due to their versatility in control representation. By extending Luisa [Zheng et al. 2022], we implement an asymmetric, stackless coroutine model with programming language support and multiple built-in schedulers for modern GPUs. To showcase the effectiveness of our model and implementation, we examine them in different application scenarios, including path tracing, SDF rendering, and incorporation with custom passes.

Event Type
Technical Papers
TimeFriday, 6 December 20243:43pm - 3:54pm JST

LocationHall B5 (2), B Block, Level 5


