

Dance-to-Music Generation with Encoder-based Textual Inversion
Session(Do) Make Some Noise
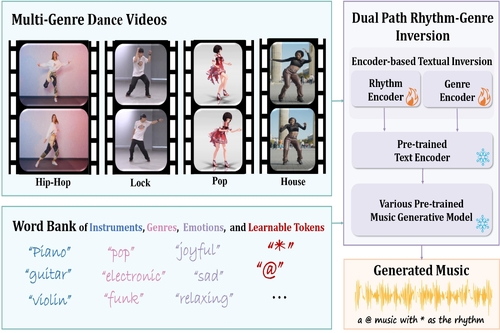
DescriptionThe seamless integration of music with dance movements is essential for communicating the artistic intent of a dance piece. This alignment also significantly improves the immersive quality of gaming experiences and animation productions. Although there has been remarkable advancement in creating high-fidelity music from textual descriptions, current methodologies mainly focus on modulating overall characteristics such as genre and emotional tone. They often overlook the nuanced management of temporal rhythm, which is indispensable in crafting music for dance, since it intricately aligns the musical beats with the dancers' movements. Recognizing this gap, we propose an encoder-based textual inversion technique to augment text-to-music models with visual control, facilitating personalized music generation. Specifically, we develop dual-path rhythm-genre inversion to effectively integrate the rhythm and genre of a dance motion sequence into the textual space of a text-to-music model. Contrary to traditional textual inversion methods, which directly update text embeddings to reconstruct a single target object, our approach utilizes separate rhythm and genre encoders to obtain text embeddings for two pseudo-words, adapting to the varying rhythms and genres. We collect a new dataset called In-the-wild Dance Videos (InDV) and demonstrate that our approach outperforms state-of-the-art methods across multiple evaluation metrics. Furthermore, our method is able to adapt to changes in tempo} and effectively integrates with the inherent text-guided generation capability of the pre-trained model. Our source code and demo videos are available at https://github.com/lsfhuihuiff/Dance-to-music_Siggraph_Asia_2024.
Authors



Event Type
Technical Papers
TimeFriday, 6 December 20241:42pm - 1:56pm JST

LocationHall B7 (1), B Block, Level 7


