


Event TypeTechnical Papers
TimeFriday, 6 December 20241:00pm - 2:10pm JST

LocationHall B7 (1), B Block, Level 7



Presentations
| 1:00pm - 1:14pm JST | 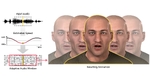 | Speed-Aware Audio-Driven Speech Animation using Adaptive Windows Technical Papers Fast Forward Presenter | |
| 1:14pm - 1:28pm JST | 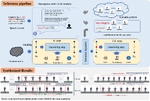 | SIGGesture: Generalized Co-Speech Gesture Synthesis via Semantic Injection with Large-Scale Pre-Training Diffusion Models | |
| 1:28pm - 1:42pm JST | 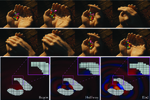 | WaveBlender: Practical Sound-Source Animation in Blended Domains | |
| 1:42pm - 1:56pm JST |  | Dance-to-Music Generation with Encoder-based Textual Inversion | |
| 1:56pm - 2:10pm JST |  | Sketching With Your Voice: "Non-Phonorealistic" Rendering of Sounds via Vocal Imitation |